講題 : Large-scale Sequence Pattern Understanding for Evolution and Human Disease Research Using Computational Approaches in a Big Data Ecosystem
Mega -> Giga -> Tera 這大概是一般人知道的十的冪次部分 (10^6 , 10^9 , 10^12)
後面的 就要看個人常識[1]廣度囉 :
Peta -> Exa -> Zetta -> Yotta .

今天 79級 徐啟仁 學長 在 逢甲 資電203 , 分享了 Big data 的理論與實務經驗 , 相當有意思 , 像是 :
如何在 基因定序後 , 不同物種基因資訊之中 , 找出重複的排列資訊 ;
如何在 更平價的設備 , 做到更高效能 (10x)的計算效能 ;
如何設計演算原則 , 以降低計算儲存等等資源需求 ?
這類的生物醫學資訊工程與理論 , 在海量資訊的過濾比對之後 ,
可以用於 基因 遺傳 疾病 演化 等等的領域 , 是相當有意義的發展方向 .
[1] http://searchstorage.techtarget.com/definition/Kilo-mega-giga-tera-peta-and-all-that
參考文件 :
J. Reneker, E. Lyons, G. C. Conant, J. C. Pires, M. Freeling, C.-R. Shyu, and D. Korkin, “Long identical multispecies elements in plant and animal genomes,” Proceedings of the National Academy of Sciences, vol. 109, pp. E1183-E1191, 2012.
H. Cao, M. Phinney, D. Petersohn, B. Merideth, and C. -R. Shyu, MRSMRS: Mining Repetitive Sequences in a MapReduce Setting, IEEE BIBM, Nov 2-6, 2014, Belfast Ireland.
活動公告網址 :
http://www.iecs.fcu.edu.tw/wSite/ct?xItem=117195&ctNode=16710&mp=370201
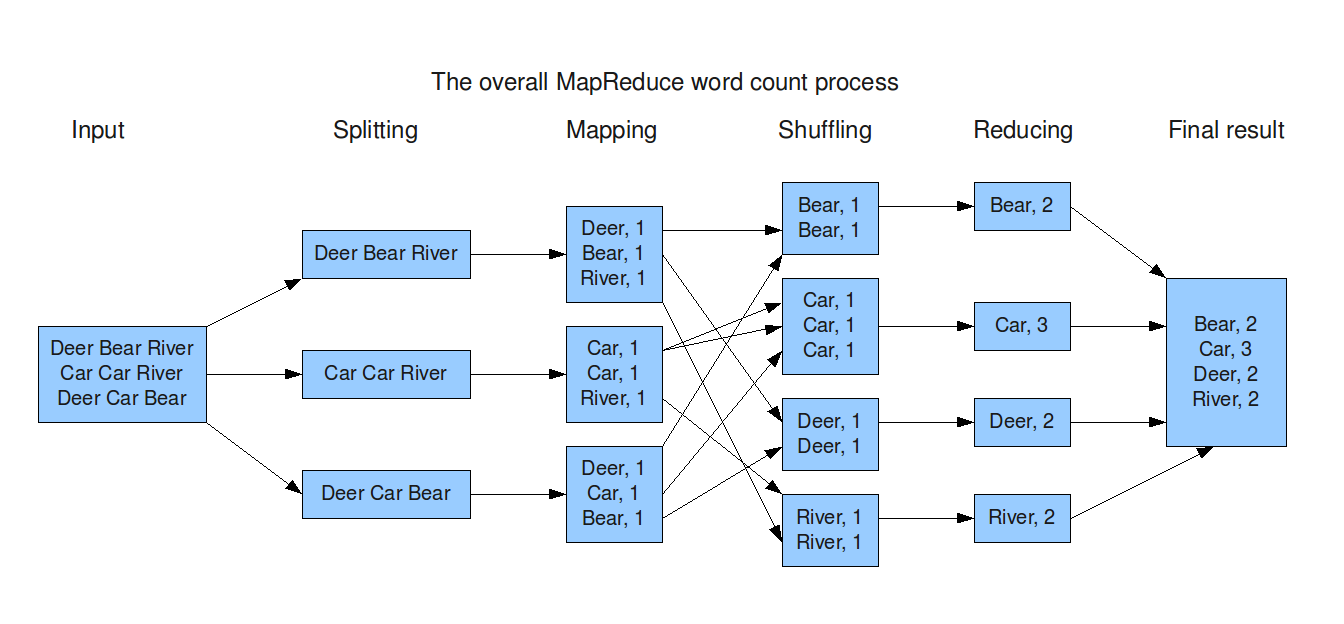
簡報中 也提到了這個 MapReduce 策略 :
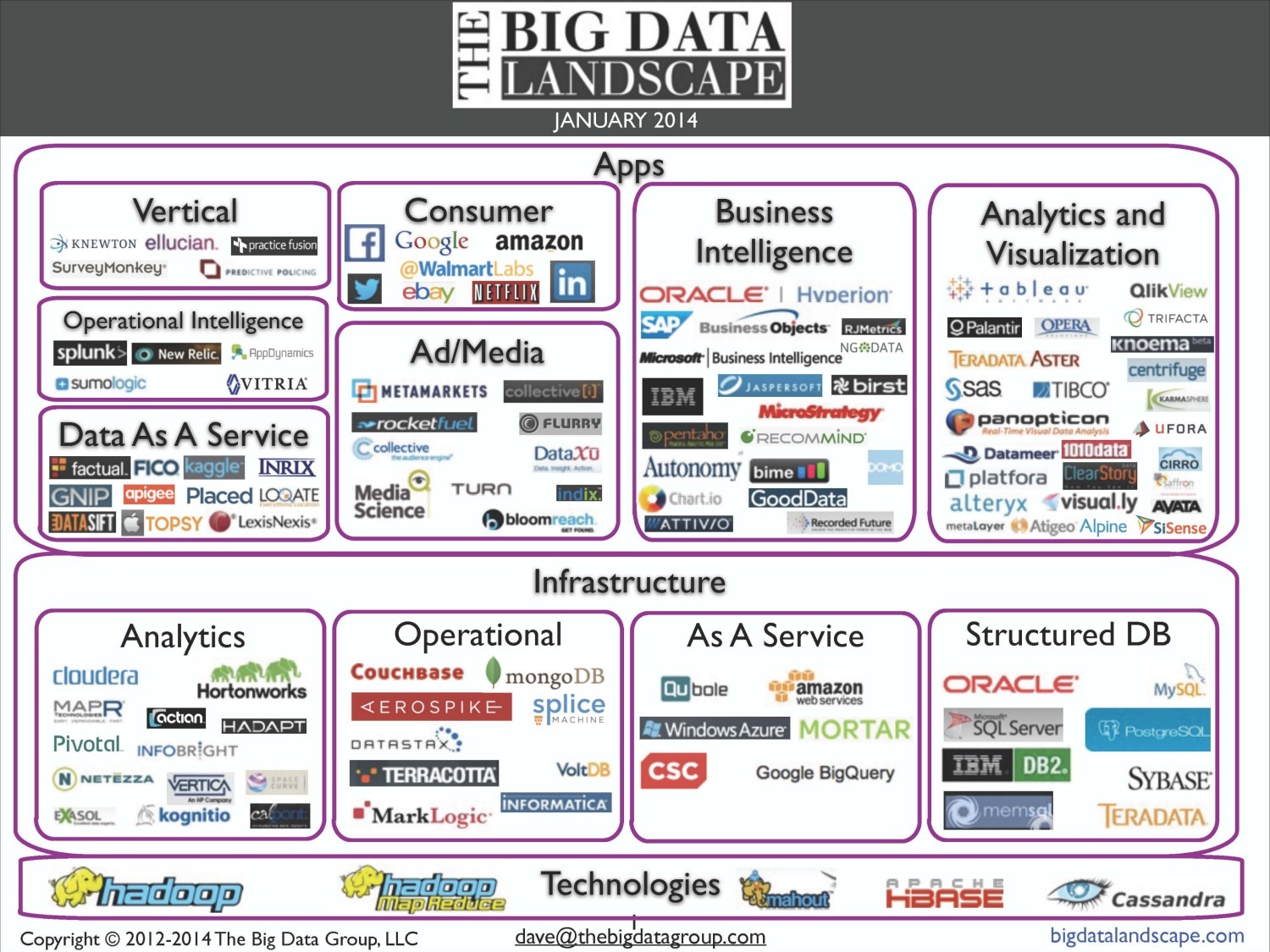
以及 Hadoop , 還有採用 NoSQL 的 HBase 的原因 (對比 MySQL 這類關連性 資料庫) ,
海量資料不在意 欄位間的關聯性 , HBase 讓 :
1. 儲存 更有效率 與
2. 增加欄 更具彈性 .