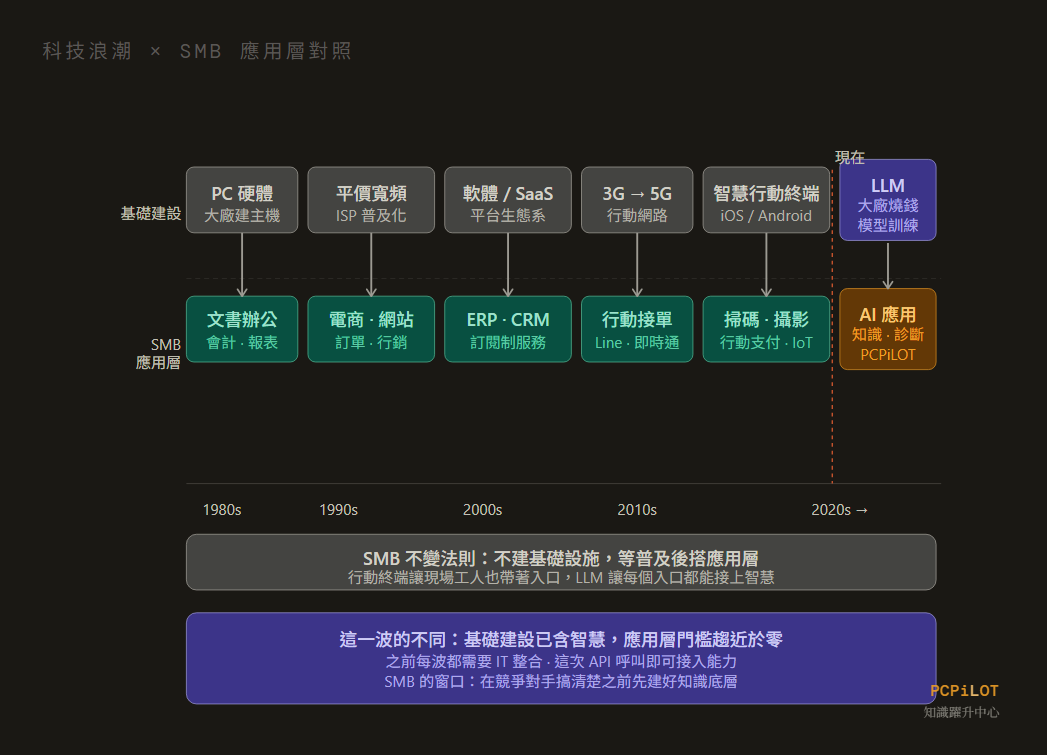

概念比喻手冊:當 20 瓦的「智慧城市」遇見吃電的「超級工廠」
1. 前言:為什麼我們需要比喻?
在人工智慧席捲全球的時代,「70B 參數」、「兆級 Token」或「突觸可塑性」等術語充斥於媒體,但對大多數人來說,這些數位是冰冷且抽象的。700 億個參數聽起來驚人,但它在生物演化奇蹟面前究竟處於什麼位置?20 瓦的能源消耗聽起來微弱,但它如何支撐起複雜的意識?
直接理解底層邏輯對大眾而言極其困難。本手冊旨在透過「智慧城市」與「超級工廠」的對比,將技術指標轉化為直覺的認知圖景。
「人類不是輸在規模,而是贏在架構與效率。」——這不僅是生物演化的勝利,更是我們面對 AI 時代的底氣。
接下來,讓我們從最基礎的「藍圖規模」開始,看看這兩座截然不同的運算體是如何構建的。
——————————————————————————–
2. 第一單元:藍圖對決——參數、突觸與複雜度
當我們談論 70B 模型(如 Llama 3)時,我們是在談論一個結構固定、邏輯稠密的「超級工廠」。而人腦,則是一座擁有驚人擴展性、每秒都在重組道路的「智慧城市」。
「70B 模型」與「人腦」核心對比表
| 維度 | 70B 模型 (如 Llama 3) | 人腦 (Human Brain) |
| 基本單元 | 700 億個參數 (權重) | 約 860 億個神經元 |
| 連接數量 | 靜態矩陣,參數即連接 | 約 100 兆 (100 Trillion) 個突觸連接 |
| 記憶容量 | 約 140 GB (FP16 格式) | 約 1–2.5 PB (100 萬至 250 萬 GB) |
| 結構特性 | 固定的層級結構 (Transformer) | 極度稀疏且具備神經塑性 (Plasticity) |
| 複雜度類比 | 密集且標準化的生產線 | 規模大 1,400 倍且自我進化的交通網 |
💡 深度洞察:莫把「語言皮質」當成「全腦」 很多人誤以為 70B 模型已經接近人腦。事實上,目前的 LLM 僅相當於人腦中「語言皮質區」的一小部分。人腦不僅擁有 1,400 倍於 70B 的連接複雜度,其 PB 等級的記憶容量更讓當前最強大的伺服器望塵莫及。此外,腦部採用非同步的「脈衝訊號 (Spikes)」,而非 GPU 的同步矩陣運算,這是極速與極效的分水嶺。
轉折句: 規模與容量的巨大差距只是開端,這兩者在運行時消耗的能量,更展現了效率上的天壤之別。
——————————————————————————–
3. 第二單元:能源之戰——20 瓦燈泡 vs. 核電廠級電力需求
如果把能效比擬成照明,人腦運作時就像一盞微弱的節能燈泡,而訓練頂尖 AI 模型所需的電力,則足以讓一整座城市運轉。
能源效率關鍵數據
- 人腦運作功耗: 約 20 瓦 (Watts)。僅靠兩顆香蕉提供的能量,就能處理思考、感知與生理調度。
- 70B 模型推論功耗: 若在本地運行,約需 200–500 瓦。
- 尖端模型訓練功耗:
- XAI Colossus 叢集: 需 260 MW (兆瓦) 持續供電。
- 2028 年預期規模: 預計單一資料中心將達 5 GW (吉瓦),相當於 數座核電廠 的總發電量。
比喻視覺化:為什麼差異這麼大?
- 智慧城市(人腦)的「稀疏啟動」: 這座城市極度節能,只有當某個區域有事件發生(事件驅動)時才會開燈,同時活化的神經元低於 1%。
- 超級工廠(LLM)的「全量計算」: 傳統 AI 運作時,每一顆螺絲(參數)都必須參與運算,整個廠區燈火通明,即便處理一個簡單的問句,也要調動密集的矩陣運算。
轉折句: 這種節能奇蹟,歸功於人腦獨特的「分層管理」架構。
——————————————————————————–
4. 第三單元:運行邏輯——三層架構 vs. 單一序列
人腦並非像 CPU 在跑「多執行緒」,而是一座非同步、多層級運作的城市。
人腦的三層處理架構與數據頻率
- 底層:城市基礎建設(自動化系統)
- 對應內容: 反射、呼吸、感覺輸入(視覺、聽覺、觸覺)。
- 數據頻率: 最高 (約 10^7 bits/s)。
- 意識介入: 幾乎為 0。就像水電管路自動運行,不佔用市長(意識)的精力。
- 中層:流動的交通(半自動背景)
- 對應內容: 習慣性動作、情緒持續調節、即時閉迴路控制 (Closed-loop Control)。
- 數據頻率: 中等。
- 意識介入: 部分可介入。如開車或走路,平時自動運行,必要時意識可接管。
- 頂層:市長辦公室(意識核心)
- 對應內容: 複雜推理、計畫、語言生成。
- 數據頻率: 極低 (僅 10–50 bits/s)。
- 意識介入: 100% 佔用。這是系統的「瓶頸」,但負責決定城市的方向。
📌 關鍵術語解釋:馮紐曼瓶頸 (Von Neumann Bottleneck) 傳統電腦架構中,「運算」與「記憶」是分開的,數據往返搬運消耗了 80% 的能量。人腦則是**「存算一體」**,突觸既負責存儲也負責運算。 比喻: GPU 像是「速度極快但笨重的重型卡車」,而人腦則是「動作緩慢但極度分散且協同的螞蟻群」。
相較之下,70B 模型屬於**「單一序列計算」**,必須 Token-by-token 逐一處理,缺乏背景自動化程序。
轉折句: 這種深層的架構差異,直接導致了學習效率上的巨大鴻溝。
——————————————————————————–
5. 第四單元:學習效率——Few-shot 原生體 vs. 海量資料吞噬者
在學習新知識時,人腦與 AI 的「食量」完全不同。
- LLM:吞掉整座圖書館的怪獸 為了學會講話,它必須吞噬數兆 (Trillions) 個 Token。這相當於要讀完人類文明幾千年來所有的書籍,才能掌握基本的對話邏輯。
- 人類:Few-shot learning(少樣本學習)原生體 一個幼兒只需要在幾百萬詞的環境中(僅為 LLM 的百萬分之一),就能舉一反三,學會母語並展現出驚人的泛化能力。
[學習效率比對圖描述] 畫面左側是一隻如山巨大的「數據怪獸」,正張開血盆大口吞噬一整座被吊車吊起的圖書館;畫面右側是一個坐在積木堆裡的幼兒,僅僅看著三本繪本,腦中就綻放出無數個連結的光點,連接到真實世界的貓、狗與蘋果。
核心差異:人類贏在「架構與泛化」。 我們不需要看過一萬張圖片才知道那是「火」,這種對物理世界的直覺理解是生物智慧的基因紅利。
轉折句: 這種學習效率與對複雜情境的適應力,正是人類在職場上依然穩坐釣魚台的原因。
——————————————————————————–
6. 第五單元:雇主視角——為什麼 20 瓦的「超算」依然無可取代?
對於中小企業 (SMB) 來說,人類員工不只是「勞動力」,更是具備極高「性價比」的通用處理器。
中小企業 (SMB) 決策對照表
| 維度 | 機器人 / 專用 AI 系統 | 人類員工 |
| 初期投入 (CAPEX) | 極高。需採購、整合與改裝環境。 | 極低。主要是招募成本。 |
| 運營支出 (OPEX) | 電力、授權金、維護成本。 | 薪資、保險、獎金。 |
| 適應性 (Agility) | 專才但僵硬。改功能需重新編程。 | 多模態彈性。能處理報價也能安撫情緒。 |
| 異常處置 | 遇到非結構化例外(客訴、突發狀況)易崩潰。 | 具備 「情境智能 (Contextual Intelligence)」。 |
| 硬體優勢 | 需額外安裝感測器。 | 自備 「預裝多模態感測器」 (五感) 與閉迴路控制。 |
關鍵比喻: 雇用人類,等同於以每月數萬元的成本,租用了一台功耗僅 20 瓦、記憶體高達 2.5 PB,且自備自動導航、情緒安撫與「自動更新軟體」功能的行動處理器。人類在處理那最棘手的 5% 非結構化例外狀況時,成本遠低於開發一套同樣能力的 AI 系統。
轉折句: 綜觀以上對比,我們可以得出一個關於智慧本質的終極結論。
——————————————————————————–
7. 結語:回歸智慧的本質
人腦並非要在規模上與 AI 進行軍備競賽,而是在架構與能效上提供了另一條演化路徑。AI 是我們強大的工具,但生物大腦依然是目前宇宙中最精密的「黑科技」。
最後三句話:
- 人腦不是更大的模型,而是完全不同的計算架構。
- 意識只是冰山一角,強大的底層自動化才是效率之源。
- 在 20 瓦的預算內,人類依然是目前最強大的「通用智能」處理器。
💡 給學習者的 3 個行動建議:
- 深耕「情境智能」(Contextual Intelligence): 磨練處理非結構化問題與人際情緒的能力,這是 AI 目前改機成本最高的地方。
- 發揮「突觸可塑性」: 不要與 AI 拼記憶量,要拼「跨領域連結」的能力。
- 利用「閉迴路控制」優勢: 強化即時感知與反應的行動力,這是具身智能 (Embodied AI) 尚未攻克的堡壘。
這邊有一段直播影片以及投影片摘要:
https://www.facebook.com/steven.lai.58511/posts/pfbid0uwyY8dqc7Rqge6Mk4sZMscnCxoieHABD1mDe8HCNMfpDau1K81y8a4ULScorPVEhl